












【佳学基因检测】如何设计和评估用于基因检测的糖尿病多基因风险评估模型?
糖尿病风险评估基因检测导读:
糖尿病是世界上发展最快的慢性病之一,糖尿病患者的数量自 1980 年以来几乎翻了两番。最常见的糖尿病类型是 2 型糖尿病 (T2DM),约占所有患者的 90%。 T2DM 的危险因素包括遗传易感性,以及生活方式因素,如肥胖和缺乏运动。 T2DM 的特点是胰岛素抵抗,导致血糖控制不佳和高血糖。 这可能导致许多健康并发症,包括神经损伤、心脏病和肾衰竭,估计全球负担为 3.1 万亿美元。
2019 年,糖尿病是全球第九大死亡原因,在 20-79 岁的成年人中,每 10 个中就有超过 1 个患有这种疾病。 到 2045 年,患病率预计将上升 45% 左右,预计中低收入国家的增幅最大。 中国的糖尿病患者人数居世界第二,占所有患者的六分之一。 在高遗传易感性和日益恶化的生活方式因素的推动下,预计到 2045 年中国的糖尿病患病率将进一步增加 74%。未确诊或未控制的 T2DM 病例可导致微血管和大血管损伤。 微血管疾病的发展可导致视力受损(视网膜病变)、肾脏损伤(肾病)、神经损伤(神经病)和截肢等并发症。 由大血管损伤引起的心血管疾病是糖尿病患者死亡的主要原因,通常由冠心病、中风和外周动脉疾病引起。
低诊断率加剧了中国 T2DM 的负担,估计有 57% 的糖尿病患者未被确诊。 这使得许多糖尿病患者得不到治疗并出现并发症,之后大部分医疗费用都自掏腰包。 以残疾调整生命年 (DALY) 衡量时,疾病流行率高和医疗保健不足的结合导致 T2DM 在中国的非传染性疾病中具有最高的健康负担。
T2DM 是一种多因素疾病,风险主要由生活方式因素驱动,例如肥胖、缺乏运动和饮食不良。 中国人对 T2DM 的易感性很高,与西方国家相比,该病发病年龄更小,体重指数 (BMI) 值更低。 研究表明,与其他种族相比,在给定的 BMI 下,中国人通常具有更高的体脂和更高的中心性肥胖,以及更大的血脂异常和胰岛素抵抗倾向。 散居中国的糖尿病患病率高于这些国家的本地人口,也证明了 T2DM 易感性的增加。 T2DM 也是一种具有高度遗传性的多基因疾病。 全基因组关联研究 (GWAS) 已经确定了超过 150 个基因座,这些基因座贡献了大约 10-15% 的遗传易感性,尽管对中国人群的综合研究仍然有限。
如何设计和评估用于基因检测的糖尿病多基因风险评估模型?
糖尿病风险评估基因检测的研究是基于 UKB 项目进行的,这是佳学基因赖以依赖的的前瞻性队列研究数据。 在 2006 年至 2010 年的基线评估访问期间,从英国招募了近 50 万年龄在 40-69 岁的参与者。 收集样本(例如血液、尿液和唾液)。 然后,它将生物样本中包含的有限信息转换为广泛共享的队列范围基因分型和全外显子组测序数据。 有关 UKB 项目的研究设计、方法和参与者的更多详细信息已在别处提供)。
最初从 UKB 收集了总共 487,409 个具有可用基因分型阵列的个体和总共 625,394 个变异。糖尿病风险评估的多基因检测模型执行了 Marees 等人描述的严格质量控制 (QC) 步骤。 (2018) 基于来自 https://www.cog-genomics.org/plink2 的 PLINK 2.0。 具体来说,糖尿病风险评估首先过滤掉 SNP 和缺失程度非常高的个体。 基于 0.2 (>20%) 的宽松阈值,糖尿病风险评估删除了 89,752 个变体和 30,855 个受试者。 还有 262,751 个 SNPs 被移除,次要等位基因频率 <0.03,1,204 个 SNPs 被移除,Hardy-Weinberg 平衡 Fisher 正确检验的 p 值 < 1×10−6。 最后,456,451 个个体和 271,687 个变体通过了 QC,并被纳入以下分析。
T2D 的确定基于自我报告、国际疾病分类第九版 (ICD-9) 代码 25000 和 25010 以及国际疾病分类第十版 (ICD-10) 代码 E11 的组合 . T2D 相关风险因素的个体水平数据,包括性别、年龄、身体指标 [例如 BMI、腰围 (WC)、DBP 和 SBP] 和临床因素 [例如 GL、CL、TL、高密度 UKB 项目还收集了脂蛋白 (HDL)、低密度脂蛋白 (LDL)]。 糖尿病多基因检测风险评估通过它们的方式进一步估算了这些因素不可避免的缺失值。 为了分析具有相对同质血统的个体,人口是根据自我报告的血统和使用前 10 个主要成分(即 PC1,…,PC10)的遗传确认血统的组合集中构建的。 为了构建、测试和进一步验证 T2D 多基因预测因子的稳健性,糖尿病风险评估将整体数据随机分为两部分,即测试和验证数据集。 糖尿病风险评估基因检测分配了所有个体的 40% 作为 UKB 测试数据集 (n = 182,422),其余 60% 作为 UKB 验证数据集 (n = 274,029)。 还尝试了其他比率来划分测试和验证数据集,即 30-70%、50-50%、60-40% 和 70-30%。 UKB 验证数据集中的个体与 UKB 测试数据集中的个体不同。 研究设计的详细信息如图 1 所示。
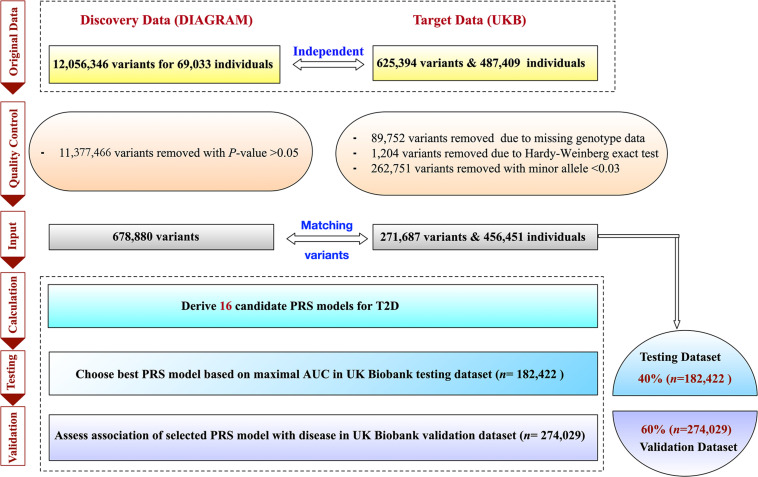
图 1:2 型糖尿病多基因风险评分 (PRS) 模型评估与建立的流程图
全基因组多基因评分构建、测试和验证
佳学基因多基因风险评估模型《PRS 模型》是用于评估多个基因的共同作用,从而提供遗传因素对疾病风险发生的影响。通常,PRS 模型可以是未加权的或加权的。 假设我们有 n 个受试者和 K 个通过第一步过滤程序的 SNP。 未加权的 PRS 模型定义为:,
其中 Gk(k = 1,….,K) 表示在加性遗传模型下编码为 0、1 或 2 的每个遗传变异的风险等位基因数。 对于加权 PRS 模型,权重通常根据与给定疾病的关联强度分配给每个遗传变异。 加权 PRS 模型可以写成,
PRSw=β^1G1+…,β^KGk,
其中 β^k(k=1,…,K) 是外部大规模 GWAS 中边际遗传效应的估计。 未加权或加权 PRS 模型均可由 PRSice-2 软件实施。
对于 PRS 模型构建,糖尿病多基因风险评估使用了来自 60,786 名参与者的 T2D GWAS 的汇总统计数据,其中包含 12,056,346 个欧洲血统的 SNP2。 请注意,UKB 样本与发现 GWAS 中的样本不重叠。 佳学基因糖尿病多基因风险评估首先根据从上述 GWAS 获得的关联 p 值 (p≤‹5׋10−2) 选择 SNP,并保留了 50,224 个 SNP。 然后,根据 Khera 等人的建议,佳学基因糖尿病风险评估考虑了多个 r2 阈值(0.2、0.4、0.6 和 0.8) 和 p 值阈值(5×10-2,5×10-4,5×10-6 和 5×10-8)也在 DIAGRAM 摘要数据集上进行第二和第三次过滤程序。 基于具有 182,422 名参与者的 UKB 测试数据集,为 T2D 创建了总共 16 个候选 PRS 模型。
具有最佳判别正确度的 PRS 模型是根据以下逻辑回归模型中的最大 AUC 确定的,该模型针对性别、年龄和祖先的前 10 个主要成分进行了调整。 佳学基因糖尿病风险基因检测评估使用 X1,X2 和 PC = (PC1,…,PC10)T 分别表示性别、年龄和祖先的前 10 个主成分的值,其中 T 表示向量或矩阵的转置。 令 Y 为 T2D 状态,其中 0 和 1 代表对照和病例。 T2D 的预测模型可以表示为,

其中 β0 是截距,β1、β2、βPC=(βPC1,…,βPC10),βg 是 X1、X2、PC 和 PRSw 的回归系数。 然后,AUCs 可以用梯形计算 (Fawcett, 2006),它们的 95% 置信区间 (CI) 可以用 Delong 的方法计算 (DeLong et al., 1988)。 AUC 及其 CI 都可以由 R 3.6.34 中的“pROC”包 3 直接实现。 在测试数据集中创建的最佳分数将带入后续验证步骤。
验证数据集中的统计分析
研究人群的基线特征被描述为平均值±标准偏差(M±SD)或百分比。 使用两个独立样本 t 检验或卡方检验来比较 UKB 测试和验证数据集之间的基线特征。 应用 Wilcoxon 符号秩检验来提供有关 T2D 个体和非 T2D 个体之间 PRS 差异的更多信息。 PRS 和 T2D 之间的关系是在 UKB 验证数据集中基于对性别、年龄和祖先的前 10 个主要成分(模型 1)进行调整的逻辑回归模型确定的,可以表示为,
T2D∼PRS+sex+age+PC
糖尿病风险评估基因检测根据 PRS 的百分位数将 UKB 验证数据集中的 274,029 名参与者分为 100 组,然后可以确定每组内的 T2D 患病率。
为了进一步观察 PRS、性别、年龄、身体测量和其他临床危险因素对 T2D 的贡献,糖尿病多基因风险评估提供了其他四种类型的预测模型:
模型2:T2D∼sex+age+PC; (1)
模型3:T2D∼PRS; (2)
模型4:T2D~sex+age+PC+BMI+GL+CL+HDL+LDL+TL+WC+DBP+SBP;(3)
模型5:T2D~PRS+性别+年龄+PC+BMI+GL+CL+HDL+LDL+TL+WC+DBP+SBP。(4)
糖尿病风险评估基因检测已经检查并没有发现上述变量之间存在共线性。 以上所有统计分析均使用 R 3.6.3 版软件进行。
- 【佳学基因检测】糖尿病的正确用药基因解码:离子通道突变基因检测...
- 【佳学基因检测】如何设计和评估用于基因检测的糖尿病多基因风险评估模型?...
- 【佳学基因检测】糖尿病药物齐格列酮使用前需要做基因检测吗?...
- 【佳学基因检测】糖尿病药物repaglinide瑞格列奈正确使用基因检测...
- 【佳学基因检测】阿尔法1型糖苷酶抑制剂糖尿病药物基因检测正确性评估标准...
- 【佳学基因检测】如果没有做基因检测,糖尿病用药至少要知道这些要点...
- 【佳学基因检测】二甲双胍用药指导基因检测——药物作用靶点的基因解码分析...
- 【佳学基因检测】糖尿病治疗药物维达列汀会有并发症出现吗?怎么做基因检测?...
- 【佳学基因检测】糖尿病基因检测包括甲苯磺丁脲用药指导吗?...
- 【佳学基因检测】妥拉唑胺基因检测可以避免无效用药,检测机构可以确定!...
- 【佳学基因检测】糖尿病药物西他列汀有用药指导基因检测了!...
- 【佳学基因检测】这个糖尿病正确用药基因检测包含沙格列汀!太好了!...
- 【佳学基因检测】如何通过基因检测判断瑞格列奈是否适合糖尿病患者?...
- 【佳学基因检测】格列吡嗪可以控制我的血糖吗?基因检测的好处有哪些?...
- 【佳学基因检测】格列美脲基因检测是如何降低糖尿病的并发症的?...
- 【佳学基因检测】glibenclamide格列苯脲基因检测单位列表...
- 【佳学基因检测】氯磺丙脲片控制血糖效果怎么样?基因检测有答案...
- 【佳学基因检测】糖尿病药物阿格列汀适合你吗?基因检测告诉你...
- 来了,就说两句!
-
- 最新评论 进入详细评论页>>
